 |
| Photo by Clint Adair on Unsplash |
Nowadays, we all must have seen and used various effects and filters on images and how our computers and smartphones detect and recognize faces in photographs and videos. These all things are possible by "computer vision" which is nothing but machine learning using convolutional neural networks.
Computer vision is similar to human vision, it helps the system to recognize, classify, detect complex features in data. Some of its applications can be seen in self-driving cars, vision for robots, facial recognition.
But this computer vision is not completely the same as our human vision, unlike us the computer sees the image in the form of a matrix of pixels.
An image is made up of pixels. And each pixel value can take a value from 0 to 255.
What is a convolutional neural network
A convolutional neural network or CNN is a kind of neural network that is used in processing data with input shape in 2D matrix form like images.
The structure of a convolutional neural network is a feed-forward with several hidden layers in the sequence mainly convolution and pooling layers followed by activation layers. With this CNN model, we can recognize handwritten letters and human faces (depending on the number of layers and complexity of the image).
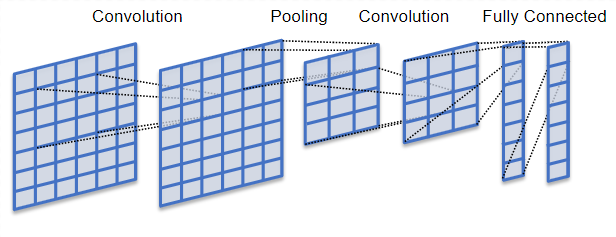 |
| (Image by Wikimedia Commons) Convolutional neural network model |
In this article, we will learn concepts of CNN and build an image classifier model for a better grasp of the subject.
Before building the model we need to understand and learn few important concepts of convolutional neural networks.
- As we already know, computers view images as numbers in the form of a matrix of pixels. CNN views images as three-dimensional objects where height and width are the first two dimensions and color encoding is the third dimension (for example, 3x3x3 RGB images).
Now just imagine, how computationally intensive it will be to process a 4K image (3840 x 2160 pixel).
Convolution
- So the main objective of convolutional networks is to reduce the images into the form which is easier to process while preserving the features and maintaining a good accuracy while predicting.
- A feature detector is a kernel of filter (a matrix of numbers, usually 3x3). Here the idea is to multiply the matrix representation of images, element-wise with the kernel to get a feature map. In this step, the size of the image is reduced for faster and simpler processing. Important features of the image are retained (like features that are unique to the image/object i.e. necessary for the recognition). However, some features are lost in this step.
- For example, if we have an input image of 5x5x1 dimensions and the convolution kernel/filter we apply to an image is of 3x3x1 dimension:
ReLu activation function
Pooling layer
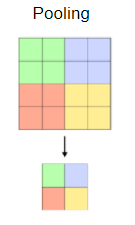
- Max pooling extracts the maximum value from the portion of the feature map matrix covered by the kernel (specific pool size like 2x2).
- Min pooling extracts the minimum value from the portion of the feature map matrix covered by the kernel (specific pool size like 2x2).
- While average pooling average of all values is selected from the portion of the feature map matrix covered by the kernel (specific pool size like 2x2).
Flattening
Full connection layer - Classification
Implementation of CNN using MNIST dataset

With a test accuracy >98% we can say that our model is trained well for accurate prediction. You can also visualize these results using the matplotlib library!
Conclusion
I hope with this article you will be able to understand and grasp the concepts of convolutional neural networks.For a better understanding of these concepts, I will recommend you try writing these codes on your once. Keep exploring, and I am sure you will discover new features along the way.
If you have any questions or comments, please post them in the comment section.

This comment has been removed by the author.
ReplyDeleteGreat Article
DeleteConvolutional Neural Networks (CNNs) are a specialized type of artificial neural network designed to process data that has a grid-like structure, such as images. They have been instrumental in revolutionizing image and video recognition, natural language processing, and other fields.
DeleteImage Processing Projects For Final Year
Core Components of a CNN
Convolutional Layer: The core building block, applying filters to extract features from the input image.
Pooling Layer: Reduces the dimensionality of the feature maps, while preserving important information.
Fully Connected Layer: Similar to traditional neural networks, used for classification or regression tasks.
It is a good site like https://www.wisdommaterials.com/
ReplyDeleteThanks for Sharing the Concept for complete convolutional neural network guide with Python Technologies,
ReplyDeletePython course in Bangalore
Python Training in Bangalore
Best Python Training Institutes in Bangalore
python training institute in Bangalore
Good day! I just want to give you a huge thumbs up for your excellent info
ReplyDeleteyou have right here on this post. I will be coming back to your site for
more soon.
Hadoop Training in Bangalore
Python Training in Bangalore
AWS Training in Bangalore
UI Development training in Bangalore
Machine Learning Training in Bangalore
Machine Learning Training with Python in Bangalore
Data Science Using Python Training in Bangalore
Thank you so much for sharing these amazing tips. I must say you are an unbelievable writer, I like the way that you describe things. Please keep sharing.
ReplyDeleteGeneration of Programming Languages
Basics of Programming Language For Beginners
How To Learn app programming and Launch Your App in 3 Months
Learn Basics of Python For Machine Learning
I really appreciate you saying it’s an interesting post to read. I learn new information from your blog, you are doing a great job. Thank you for sharing meaningful information
ReplyDeleteGet Genuine Experience Certificate with Reasonable Cost
Want Fill Your Career GAP ! Call Us & Get Genuine Experience Certificate
ReplyDeleteHi dear,
Thank you for this wonderful post. It is very informative and useful. I would like to share something here too.Abbiamo molte possibilità per il tuo successo professionale. Partecipa ai nostri corsi di formazione online, Partecipa ai nostri corsi di recupero online. Iniziare a imparare gratuitamente con un'ampia gamma di corsi online gratuiti che coprono diverse materie. Corsi online gratuiti per raggiungere i tuoi obiettivi, forniamo anche lezioni di recupero per gli student.
Corsi di Recupero
ReplyDeleteHi dear,
Thank you for this wonderful post. It is very informative and useful. I would like to share something here too.Our highly professional team provide complete IT solutions that specializes in custom mobile and web application development. Call us at (+91) 9001721837.
cms development company india
Hi dear,
ReplyDeleteThank you for this wonderful post. It is very informative and useful. I would like to share something here too.Loop of Words is an innovative digital marketing agency dedicated to enhancing your brand’s image and customer base. The latest tools, powerful strategies, and data-driven results are our power pillars to deliver the best results.
https://loopofwords.in/website-development/>custom web development services
Machine Learning Interview Questions and Answers
ReplyDeleteData Science Course in Delhi
ReplyDeletehttps://onlinecoursesdelhi.educatorpages.com/pages/data-science-course-in-delhi
Best Data Science training institute in Delhi helpful to improve your skills and bright future. APTRON Delhi is Good training institute for Data Science course in Delhi. All sessions are practical and based on real-time scenario.
Your blog rocks! I just wanted to say that your blog is awesome. It’s really helped me to chose ms in machine learning usa.
ReplyDelete